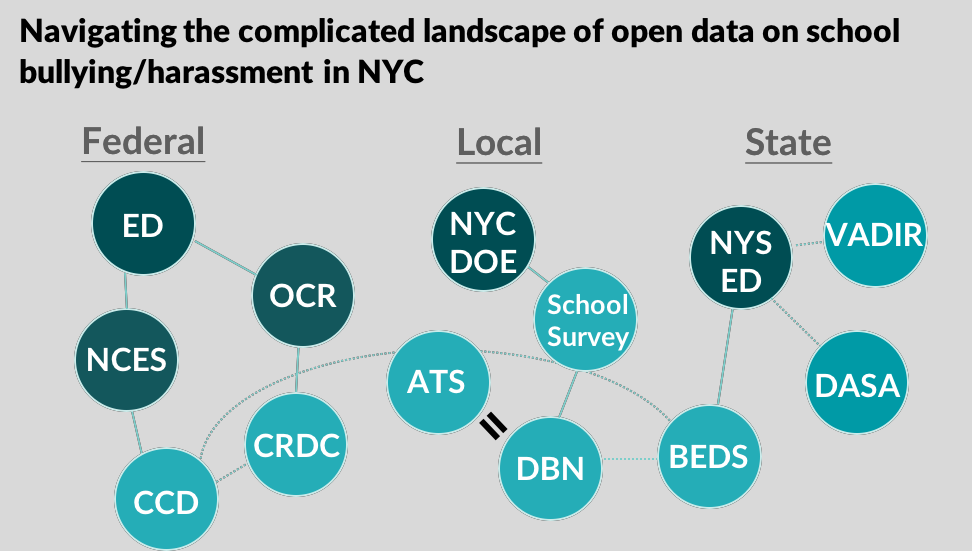

As open data portals continue to proliferate, interested parties often find that data about the same topic (e.g., school bullying) can exist on multiple levels—local, state, federal, etc. Our goal was to showcase where and why these datasets agree and disagree, by presenting the findings of our data analysis and moderating a panel discussion at an event we hosted for NYC Open Data Week 2018.
How I Started
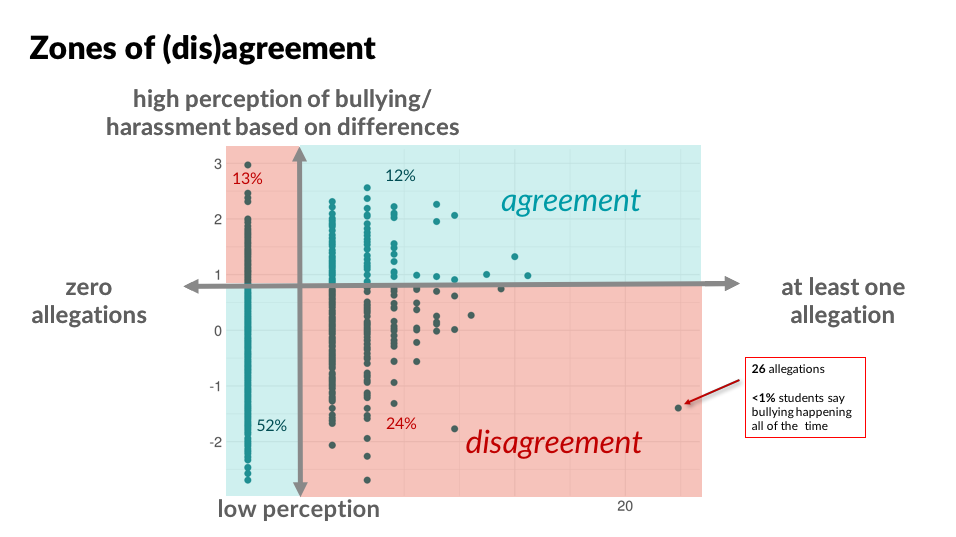
How much of a problem is school bullying in NYC? The answer depends on who you ask. We compared local surveys (most students say bullying is happening) with federal data (most schools report 0 incidents), and talked with researchers, advocates, and journalists to better understand these disparities.
Used Data
How I Built This
This project grew out of a company-wide Hack Day for Social Good event during which Two Sigma employees analyzed data from the federal Office for Civil Rights survey of public schools nationwide. In February 2018, we decided to submit an idea around comparing NYC Open Data assets with federal data sources for NYC Open Data Week 2018. It took us considerable time to create a crosswalk of school IDs between the two datasets (because schools are labeled differently in the NYC data than in the federal reporting), which we have provided as open data here (https://github.com/tsdataclinic/open-data-week/blob/master/data/output/crosswalk.csv). We also used several other NYC Open Data assets, like the School Locations file, the Annual Enrollment Snapshots, and the Class Size reports, to examine whether schools with certain characteristics are more or less likely to report more bullying or to have disparities between the local and federal reporting. To add context to our quantitative analysis, for the event itself, we invited a panel of researchers, advocates, and other experts in the field of education to discuss the uses and limitations of the different datasets.
We used Python (pandas, statsmodels, scikit-learn) for the data processing, analysis, and modeling and R (dplyr, ggplot2) for the main visualizations. We stored files in the feather format (https://blog.cloudera.com/blog/2016/03/feather-a-fast-on-disk-format-for-data-frames-for-r-and-python-powered-by-apache-arrow/) to optimize compatibility between the two programming languages. The code for the analysis is open-sourced on GitHub here: https://github.com/tsdataclinic/open-data-week and the write-up of our findings with our slides and video presentation is here: https://www.twosigma.com/insights/article/data-clinic-what-we-learned-from-open-data-on-bullying-and-harassment-in-nyc-schools/.